Ранее мы рассмотрели применение инструкции SELECT для выборки данных из одной таблицы базы данных. Если бы возможности языка Transact-SQL ограничивались поддержкой только таких простых инструкций SELECT, то присоединение в запросе двух или больше таблиц для выборки из них данных было бы невозможно. Следственно, все данные базы данных требовалось бы хранить в одной таблице. Хотя такой подход является вполне возможным, ему присущ один значительный недостаток - хранимые таким образом данные характеризуются высокой избыточностью.
Язык Transact-SQL устраняет этот недостаток, предоставляя для этого оператор соединения JOIN , который позволяет извлекать данные более чем из одной таблицы. Этот оператор, наверное, является наиболее важным оператором для реляционных систем баз данных, поскольку благодаря ему имеется возможность распределять данные по нескольким таблицам, обеспечивая, таким образом, важное свойство систем баз данных - отсутствие избыточности данных.
Оператор UNION, который мы рассмотрели ранее, также позволяет выполнять запрос по нескольким таблицам. Но этот оператор позволяет присоединить несколько инструкций SELECT, тогда как оператор соединения JOIN соединяет несколько таблиц с использованием всего лишь одной инструкции SELECT. Кроме этого, оператор UNION объединяет строки таблиц, в то время как оператор JOIN соединяет столбцы.
Оператор соединения также можно применять с базовыми таблицами и представлениями. Оператор соединения JOIN имеет несколько разных форм. В этой статье рассматриваются следующие основные формы этого оператора:
естественное соединение;
декартово произведение или перекрестное соединение;
внешнее соединение;
тета-соединение, самосоединение и полусоединение.
Прежде чем приступить к рассмотрению разных форм соединений, в этом разделе мы рассмотрим разные варианты оператора соединения JOIN.
Две синтаксические формы реализации соединений
Для соединения таблиц можно использовать две разные синтаксические формы оператора соединения:
явный синтаксис соединения (синтаксис соединения ANSI SQL:1992);
неявный синтаксис соединения (синтаксис соединения "старого стиля").
Синтаксис соединения ANSI SQL:1992 был введен стандартом SQL92 и определяет операции соединения явно, т.е. используя соответствующее имя для каждого типа операции соединения. При явном объявлении соединения используются следующие ключевые слова:
-
LEFT JOIN;
RIGHT JOIN;
FULL JOIN.
Ключевое слово CROSS JOIN определяет декартово произведение двух таблиц. Ключевое слово INNER JOIN определяет естественное соединение двух таблиц, а LEFT OUTER JOIN и RIGHT OUTER JOIN определяют одноименные операции соединения. Наконец, ключевое слово FULL OUTER JOIN определяет соединение правого и левого внешнего соединений. Все эти операции соединения рассматриваются в последующих разделах.
Неявный синтаксис оператора соединения является синтаксисом "старого стиля", где каждая операция соединения определяется неявно посредством предложения WHERE, используя так называемые столбцы соединения.
Для операций соединения рекомендуется использовать явный синтаксис, т.к. это повышает надежность запросов. По этой причине во всех примерах далее, связанных с операциями соединения, используются формы явного синтаксиса. Но в нескольких первых примерах также будет продемонстрирован и синтаксис "старого стиля".
Естественное соединение
Термины "естественное соединение" (natural join) и "соединение по эквивалентности" (equi-join) часто используют синонимично, но между ними есть небольшое различие. Операция соединения по эквивалентности всегда имеет одну или несколько пар столбцов с идентичными значениями в каждой строке. Операция, которая устраняет такие столбцы из результатов операции соединения по эквивалентности, называется естественным соединением. Наилучшим способом объяснить естественное соединение можно посредством примера:
USE SampleDb; SELECT Employee.*, Department.* FROM Employee INNER JOIN Department ON Employee.DepartamentNumber = Department.Number;
Запрос возвращает всю информацию обо всех сотрудниках: имя и фамилию, табельный номер, а также имя, номер и местонахождение отдела, при этом для номера отдела отображаются дубликаты столбцов из разных таблиц.
В этом примере в инструкции SELECT для выборки указаны все столбцы таблиц для сотрудника Employee и отдела Department. Предложение FROM инструкции SELECT определяет соединяемые таблицы, а также явно указывает тип операции соединения - INNER JOIN . Предложение ON является частью предложения FROM и указывает соединяемые столбцы в обеих таблицах. Выражение "Employee.DepartamentNumber = Department.Number" определяет условие соединения, а оба столбца условия называются столбцами соединения .
Эквивалентный запрос с применением неявного синтаксиса ("старого стиля") будет выглядеть следующим образом:
Эта форма синтаксиса имеет два значительных различия с явной формой: список соединяемых таблиц указывается в предложении FROM, а соответствующее условие соединения указывается в предложении WHERE посредством соединяемых столбцов.
На предыдущих примерах можно проиллюстрировать принцип работы операции соединения. Но при этом следует иметь в виду, что это всего лишь представление о процессе соединения, т.к. в действительности компонент Database Engine выбирает реализацию операции соединения из нескольких возможных стратегий. Представьте себе, что каждая строка таблицы Employee соединена с каждой строкой таблицы Department. В результате получится таблица с семью столбцами (4 столбца из таблицы Employee и 3 из таблицы Department) и 21 строкой.
Далее, из этой таблицы удаляются все строки, которые не удовлетворяют условию соединения "Employee.Number = Department.Number". Оставшиеся строки представляют результат первого примера выше. Соединяемые столбцы должны иметь идентичную семантику, т.е. оба столбца должны иметь одинаковое логическое значение. Соединяемые столбцы не обязательно должны иметь одинаковое имя (или даже одинаковый тип данных), хотя часто так и бывает.
Система базы данных не может определить логическое значение столбца. Например, она не может определить, что между столбцами номера проекта и табельного номера сотрудника нет ничего общего, хотя оба они имеют целочисленный тип данных. Поэтому система базы данных может только проверить тип данных и длину строк. Компонент Database Engine требует, что соединяемые столбцы имели совместимые типы данных, например INT и SMALLINT.
База данных SampleDb содержит три пары столбцов, где каждый столбец в паре имеет одинаковое логическое значение (а также одинаковые имена). Таблицы Employee и Department можно соединить по столбцам Employee.DepartmentNumber и Department.Number. Столбцами соединения таблиц Employee и Works_on являются столбцы Employee.Id и Works_on.EmpId. Наконец, таблицы Project и Works_on можно соединить по столбцам Project.Number и Works_on.ProjectNumber.
Имена столбцов в инструкции SELECT можно уточнить. В данном контексте под уточнением имеется в виду, что во избежание неопределенности относительно того, какой таблице принадлежит столбец, в имя столбца включается имя его таблицы (или псевдоним таблицы), отделенное точкой:
table_name.column_name (имя_таблицы.имя_столбца)
В большинстве инструкций SELECT столбцы не требуют уточнения, хотя обычно рекомендуется применять уточнение столбцов с целью улучшения понимания кода. Если же имена столбцов в инструкции SELECT неоднозначны (как, например, столбцы Number в таблицах Project и Department) использование уточненных имен столбцов является обязательным.
В инструкции SELECT с операцией соединения, кроме условия соединения предложение WHERE может содержать и другие условия, как это показано в примере ниже:
USE SampleDb; -- Явный синтаксис SELECT EmpId, Project.Number, Job, EnterDate, ProjectName, Budget FROM Works_on JOIN Project ON Project.Number = Works_on.ProjectNumber WHERE ProjectName = "Gemini"; -- Старый стиль SELECT EmpId, Project.Number, Job, EnterDate, ProjectName, Budget FROM Works_on, Project WHERE Project.Number = Works_on.ProjectNumber AND ProjectName = "Gemini";
Использование уточненного имени столбца Project.Number в примере выше не является обязательным, поскольку в данном случае нет никакой двусмысленности в отношении их имен. В дальнейшем во всех примерах будет использоваться только явный синтаксис соединения.
В примере ниже показано еще одно применение внутреннего соединения:
Соединение более чем двух таблиц
Теоретически количество таблиц, которые можно соединить в инструкции SELECT, неограниченно. (Но одно условие соединения совмещает только две таблицы!) Однако для компонента Database Engine количество соединяемых таблиц в инструкции SELECT ограничено 64 таблицами.
В примере ниже показано соединение трех таблиц базы данных SampleDb:
USE SampleDb; -- Вернет единственного сотрудника "Василий Фролов" SELECT FirstName, LastName FROM Works_on JOIN Employee ON Works_on.EmpId = Employee.Id JOIN Department ON Employee.DepartamentNumber = Department.Number AND Location = "Санкт-Петербург" AND Job = "Аналитик";
В этом примере происходит выборка имен и фамилий всех аналитиков (Job = "Аналитик"), чей отдел находится в Санкт-Петербурге (Location = "Санкт-Петербург"). Результат запроса, приведенного в примере выше, можно получить только в том случае, если соединить, по крайней мере, три таблицы: Works_on, Employee и Department. Эти таблицы можно соединить, используя две пары столбцов соединения:
(Works_on.EmpId, Employee.Id) (Employee.DepartmentNumber, Department.Number)
Обратите внимание, что для осуществления естественного соединения трех таблиц используется два условия соединения, каждое из которых соединяет по две таблицы. А при соединении четырех таблиц таких условий соединения требуется три. В общем, чтобы избежать получения декартового продукта при соединении n таблиц, требуется применять n - 1 условий соединения. Конечно же, допустимо использование более чем n - 1 условий соединения, а также других условий, для того чтобы еще больше уменьшить количество элементов в результирующем наборе данных.
Декартово произведение
В предшествующем разделе мы рассмотрели возможный способ создания естественного соединения. На первом шаге этого процесса каждая строка таблицы Employee соединяется с каждой строкой таблицы Department. Эта операция называется декартовым произведением (cartesian product) . Запрос для создания соединения таблиц Employee и Department, используя декартово произведение, показан в примере ниже:
USE SampleDb; SELECT Employee.*, Department.* FROM Employee CROSS JOIN Department;
Декартово произведение соединяет каждую строку первой таблицы с каждой строкой второй. В общем, результатом декартового произведения первой таблицы с n строками и второй таблицы с m строками будет таблица с n*m строками. Таким образом, результирующий набор запроса в примере выше имеет 7 х 3 = 21 строку (эти строки содержат дублированные значения).
На практике декартово произведение применяется крайне редко. Иногда пользователи получают декартово произведение двух таблиц, когда они забывают включить условие соединения в предложении WHERE при использовании неявного синтаксиса соединения "старого стиля". В таком случае полученный результат не соответствует ожидаемому, т.к. содержит лишние строки. Наличие неожидаемо большого количества строк в результате служит признаком того, что вместо требуемого естественного соединения двух таблиц было получено декартово произведение.
Внешнее соединение
В предшествующих примерах естественного соединения, результирующий набор содержал только те строки с одной таблицы, для которых имелись соответствующие строки в другой таблице. Но иногда кроме совпадающих строк бывает необходимым извлечь из одной или обеих таблиц строки без совпадений. Такая операция называется внешним соединением (outer join) .
В примере ниже показана выборка всей информации для сотрудников, которые проживают и работают в одном и том же городе. Здесь используется таблица EmployeeEnh, которую мы создали в статье "Инструкция SELECT: расширенные возможности" при обсуждении оператора UNION.
USE SampleDb; SELECT DISTINCT EmployeeEnh.*, Department.Location FROM EmployeeEnh JOIN Department ON City = Location;
Результат выполнения этого запроса:
В этом примере получение требуемых строк осуществляется посредством естественного соединения. Если бы в этот результат потребовалось включить сотрудников, проживающих в других местах, то нужно было применить левое внешнее соединение. Данное внешнее соединение называется левым потому, что оно возвращает все строки из таблицы с левой стороны оператора сравнения, независимо от того, имеются ли совпадающие строки в таблице с правой стороны. Иными словами, данное внешнее соединение возвратит строку с левой таблицы, даже если для нее нет совпадения в правой таблице, со значением NULL соответствующего столбца для всех строк с несовпадающим значением столбца другой, правой, таблицы. Для выполнения операции левого внешнего соединения компонент Database Engine использует оператор LEFT OUTER JOIN .
Операция правого внешнего соединения аналогична левому, но возвращаются все строки таблицы с правой части выражения. Для выполнения операции правого внешнего соединения компонент Database Engine использует оператор RIGHT OUTER JOIN .
USE SampleDb; SELECT EmployeeEnh.*, Department.Location FROM EmployeeEnh LEFT OUTER JOIN Department ON City = Location;
В этом примере происходит выборка сотрудников (с включением полной информации) для таких городов, в которых сотрудники или только проживают (столбец City в таблице EmployeeEnh), или проживают и работают. Результат выполнения этого запроса:

Как можно видеть в результате выполнения запроса, когда для строки из левой таблицы (в данном случае EmployeeEnh) нет совпадающей строки в правой таблице (в данном случае Department), операция левого внешнего соединения все равно возвращает эту строку, заполняя значением NULL все ячейки соответствующего столбца для несовпадающего значения столбца правой таблицы. Применение правого внешнего соединения показано в примере ниже:
USE SampleDb; SELECT EmployeeEnh.City, Department.* FROM EmployeeEnh RIGHT OUTER JOIN Department ON City = Location;
В этом примере происходит выборка отделов (с включением полной информации о них) для таких городов, в которых сотрудники или только работают, или проживают и работают. Результат выполнения этого запроса:

Кроме левого и правого внешнего соединения, также существует полное внешнее соединение, которое является объединением левого и правого внешних соединений. Иными словами, результирующий набор такого соединения состоит из всех строк обеих таблиц. Если для строки одной из таблиц нет соответствующей строки в другой таблице, всем ячейкам строки второй таблицы присваивается значение NULL. Для выполнения операции полного внешнего соединения используется оператор FULL OUTER JOIN .
Любую операцию внешнего соединения можно эмулировать, используя оператор UNION совместно с функцией NOT EXISTS. Таким образом, запрос, показанный в примере ниже, эквивалентен запросу левого внешнего соединения, показанному ранее. В данном запросе осуществляется выборка сотрудников (с включением полной информации) для таких городов, в которых сотрудники или только проживают или проживают и работают:
Первая инструкция SELECT объединения определяет естественное соединение таблиц EmployeeEnh и Department по столбцам соединения City и Location. Эта инструкция возвращает все города для всех сотрудников, в которых сотрудники и проживают и работают. Дополнительно, вторая инструкция SELECT объединения возвращает все строки таблицы EmployeeEnh, которые не отвечают условию в естественном соединении.
Другие формы операций соединения
В предшествующих разделах мы рассмотрели наиболее важные формы соединения. Но существуют и другие формы этой операции, которые мы рассмотрим в следующих подразделах.
Тета-соединение
Условие сравнения столбцов соединения не обязательно должно быть равенством, но может быть любым другим сравнением. Соединение, в котором используется общее условие сравнения столбцов соединения, называется тета-соединением . В примере ниже показана операция тета-соединения, в которой используется условие "меньше чем". Данный запрос возвращает все комбинации информации о сотрудниках и отделах для тех случаев, когда место проживания сотрудника по алфавиту идет перед месторасположением любого отдела, в котором работает этот служащий:
USE SampleDb; SELECT FirstName, LastName, City, Location FROM EmployeeEnh JOIN Department ON City
Результат выполнения этого запроса:

В этом примере сравниваются соответствующие значения столбцов City и Location. В каждой строке результата значение столбца City сравнивается в алфавитном порядке с соответствующим значением столбца Location.
Самосоединение, или соединение таблицы самой с собой
Кроме соединения двух или больше разных таблиц, операцию естественного соединения можно применить к одной таблице. В данной операции таблица соединяется сама с собой, при этом один столбец таблицы сравнивается сам с собой. Сравнивание столбца с самим собой означает, что в предложении FROM инструкции SELECT имя таблицы употребляется дважды. Поэтому необходимо иметь возможность ссылаться на имя одной и той же таблицы дважды. Это можно осуществить, используя, по крайней мере, один псевдоним. То же самое относится и к именам столбцов в условии соединения в инструкции SELECT. Для того чтобы различить столбцы с одинаковыми именами, необходимо использовать уточненные имена.
Соединение таблицы с самой собой демонстрируется в примере ниже:
В этом примере происходит выборка всех отделов (с полной информацией), расположенных в том же самом месте, как и, по крайней мере, один другой отдел. Результат выполнения этого запроса:

Здесь предложение FROM содержит два псевдонима для таблицы Department: t1 и t2. Первое условие в предложении WHERE определят столбцы соединения, а второе - удаляет ненужные дубликаты, обеспечивая сравнение каждого отдела с другими отделами.
Полусоединение
Полусоединение похоже на естественное соединение, но возвращает только набор всех строк из одной таблицы, для которой в другой таблице есть одно или несколько совпадений. Использование полусоединения показано в примере ниже:
Результат выполнения запроса:

Как можно видеть, список выбора SELECT в полусоединении содержит только столбцы из таблицы Employee. Это и есть характерной особенностью операции полусоединения. Эта операция обычно применяется в распределенной обработке запросов, чтобы свести к минимуму объем передаваемых данных. Компонент Database Engine использует операцию полусоединения для реализации функциональности, называющейся соединением типа "звезда".
Если тип_соединения явно не указан, то подразумевается INNER JOIN. Обратите внимание, что существует много типов соединений, каждый из которых имеет свои правила и функциональность, описанные в разделе «Общие правила».
Как правило, при описании соединений следует предпочитать предложение JOIN предложению WHERE. Это не только делает код более понятным и позволяет отличать условия соединения от условий поиска, но также позволяет избегать ошибок, связанных с реализациями внешних соединений с помощью предложений WHERE на некоторых платформах.
Мы, как правило, не рекомендуем использовать экономящие труд ключевые слова типа NATURAL, поскольку это предложение автоматически не обновляется при изменении структуры базовых таблиц. Следовательно, инструкции, в которых используются данные предложения, могут приводить к появлению ошибок при изменении структуры таблицы, если структура запроса не изменяется.
Не все платформы поддерживают все типы соединений, так что обращайтесь к описанию платформо-специфической поддержки соединений в соответствующих разделах.
Платформа DB2 поддерживает соединения INNER и OUTER с использованием предложения ON. Не поддерживаются синтаксические конструкции NATURAL и CROSS, а также USING. Синтаксис предложения JOIN в DB2 выглядит следующим образом.
Соединения, включающие более двух таблиц, могут быть весьма сложными. Если в соединении участвует три и более таблицы, лучше подумать о создании запроса, представляющего собой серию двухтабличных соединений.
MySQL
Платформа MySQL поддерживает большую часть синтаксиса ANSI, за исключением того, что соединения с префиксом NATURAL поддерживаются только для внешних, но не для внутренних соединений. Синтаксис предложения JOIN в MySQL следующий.
FROM таблица { | {{ | |
| [{LEFT | RIGHT | FULL} ]} JOIN соединяемая_таблица
{ON условие_соединения1 [{AND|OR} условие_соединения2] […]] | USING (столбец1 [, …])}}} […]
STRAIGHT JOIN
Заставляет оптимизатор соединять таблицы в том порядке, как они упоминаются в предложении FROM.
Ключевое слово STRAIGHTJOIN функционально эквивалентно слову JOIN, за исключением того, что соединения принудительно выполняются в порядке слева направо. Эта опция нужна, потому что MySQL может, хотя и редко, соединять таблицы в неверном порядке.
Oracle
Платформа Oracle полностью поддерживает стандартный синтаксис ANSI для предложения JOIN. Однако в Oracle поддержка синтаксиса ANSI появилась, только начиная с версии 9. Соответственно в более старом коде Oracle используются исключительно соединения с предложением WHERE. В старом синтаксисе Oracle для внешних тета-соединений поддерживалось добавление знака + к именам столбцов на стороне, противоположной внешней таблице. Старый синтаксис внешних тета-соединений в Oracle исходит из того факта, что в таблицу, поставляющую строки с пустыми значениями, эти строки были добавлены. Платформа Oracle отражает этот факт, добавляя «+» к имени столбца на стороне, противоположной направлению соединения.
Например, в следующем запросе производится соединение RIGHT OUTER JOIN таблиц authors и publishers. Старый синтаксис Oracle будет выглядеть следующим образом.
SELECT a.au_lname AS "first name", a.au_fname AS "last name", p.pub_name AS "publisher" FROM authors a, publishers p WHERE a.city(+)=p.city ORDER BY a.au_lname DESC;
Тот же самый запрос, написанный с использованием синтаксиса ANSI, будет выглядеть так.
SELECT a.au_lname AS "first name", a.au_fname AS "last name", p.pub_name AS "publisher" FROM authors AS a RIGHT OUTER JOIN publishers AS p ON a.city=p.city ORDER BY a.au_lname DESC;
Дополнительные примеры с использованием предложения JOIN приведены в разделе «Общие правила».
Платформа Oracle - единственная, которая позволяет использовать секционированные внешние соединения (partitioned outer joins), которые полезны для заполнения пустых мест в результирующих наборах, возникающих из-за фрагментированного хранения данных. Например, предположим, что записи о продукции хранятся в таблице manufacturing с двумя ключами - день и идентификатор продукта. В таблице хранятся записи, показывающие количество произведенного продукта в любой день, когда продукция производилась, но отсутствуют строки, соответствующие дням, когда продукция не производилась. Такая структура считается фрагментированной, поскольку в списке строк не отражены все дни и все продукты. Для проведения расчетов и создания отчетов хорошо бы создать такой набор данных, в котором производство каждого продукта было бы отражено по всем дням, независимо от того, производился продукт или нет. Это можно просто сделать при помощи секционированного внешнего соединения, поскольку оно позволяет определить логический раздел и применить внешнее соединение к каждому значению этого раздела. Ниже приводится пример с таблицей manufacturing, которая соединяется при помощи внешнего секционированного соединения с таблицей times, чтобы создать для каждого значения product_id полный набор дат в указанном диапазоне.
SELECT times.time_id AS time, product_id AS id, quantity AS qty FROM manufacturing PARTITION BY (product_id) RIGHT OUTER JOIN times ON (manufacturing.time_id=times.time_id) WHERE manufacturing, time_id BETWEEN TO_DATE("01/10/05", "DD/MM/YY") AND TO_DATE("06/10/05", "DD/MM/YY") ORDER BY 2, 1;
Чтобы получить такой же результат без использования секционированного внешнего соединения, нужно писать более сложный и менее эффективный код.
PostgreSQL
Платформа PostgreSQL полностью поддерживает стандарт ANSI. Примеры приводятся в разделе «Общие правила».
SQL Server
Платформа SQL Server поддерживает соединения типов INNER, OUTER и CROSS с использованием предложения ON. SQL Server не поддерживает синтаксические конструкции NATURAL и USING. Синтаксис инструкции JOIN в SQL Server следующий.
FROM таблица
{{ | | | [{LEFT | RIGHT | FULL} ]} JOIN соединяемая_таблица
{ON условие_соединения! [{AND|OR} условие_соединения2] […]]} […]
Примеры приведены в разделе «Общие правила».
Оператор языка SQL JOIN предназначен для соединения двух или более таблиц базы данных по совпадающему условию. Этот оператор существует только в реляционных базах данных. Именно благодаря JOIN реляционные базы данных обладают такой мощной функциональностью, которая позволяет вести не только хранение данных, но и их, хотя бы простейший, анализ с помощью запросов. Разберём основные нюансы написания SQL-запросов с оператором JOIN, которые являются общими для всех СУБД (систем управления базами данных). Для соединения двух таблиц оператор SQL JOIN имеет следующий синтаксис:
SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ_1 JOIN ИМЯ_ТАБЛИЦЫ_2 ON УСЛОВИЕ
После одного или нескольких звеньев с оператором JOIN может следовать необязательная секция WHERE или HAVING, в которой, также, как в простом SELECT-запросе, задаётся условие выборки. Общим для всех СУБД является то, что в этой конструкции вместо JOIN может быть указано INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN (или, как вариант, запятая).
INNER JOIN (внутреннее соединение)
Запрос с оператором INNER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON.
То же самое делает и просто JOIN. Таким образом, слово INNER - не обязательное.
Пример 1. Есть база данных портала объявлений. В ней есть таблица Categories (категории объявлений) и Parts (части, или иначе - рубрики, которые и относятся к категориям). Например, части Квартиры, Дачи относятся к категории Недвижимость, а части Автомобили, Мотоциклы - к категории Транспорт. Эти таблицы с заполненными данными имеют следующий вид.
Таблица Parts:
Заметим, что в таблице Parts Книги имеют Cat - ссылку на категорию, которой нет в таблице Categories, а в таблице Categories Техника имеет Cat_ID - первичный ключ, ссылки на который нет в таблице Parts. Требуется соединить данные этих двух таблиц так, чтобы в результирующей таблице были поля Part (Часть), Cat (Категория) и Price (Цена подачи объявления) и чтобы данные полностью пересекались по условию. Условие - совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts. Для этого пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS INNER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
В результирующей таблице нет Книг, так как эта запись ссылается на категорию, которой нет в таблице Categories, и Техники, так как эта запись имеет внешний ключ в таблице Categories, на который нет ссылки в таблице Parts.
В ряде случаев при соединениях таблиц составить менее громоздкие запросы можно с помощью предиката EXISTS и без использования JOIN.
Есть база данных "Театр". Таблица Play содержит данные о постановках. Таблица Team - о ролях актёров. Таблица Actor - об актёрах. Таблица Director - о режиссёрах. Поля таблиц, первичные и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).

Пример 3. Вывести список актеров, которые в одном спектакле играют более одной роли, и количество их ролей.
Оператор JOIN использовать 1 раз. Использовать HAVING, GROUP BY .
Подсказка. Оператор HAVING применяется к числу ролей, подсчитанных агрегатной функцией COUNT.
LEFT OUTER JOIN (левое внешнее соединение)
Запрос с оператором LEFT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой по порядку (левой) таблицы, даже если они не соответствуют условию. У записей левой таблицы, которые не соответствуют условию, значение столбца из правой таблицы будет NULL (неопределённым).

Пример 4. База данных и таблицы - те же, что и в примере 1.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Parts, которые не соответствуют условию, пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS LEFT OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
В результирующей таблице, в отличие от таблицы из примера 1, есть Книги, но значение столбца Цены (Price) у них - NULL, так как эта запись имеет идентификатор категории, которой нет в таблице Categories.
RIGHT OUTER JOIN (правое внешнее соединение)
Запрос с оператором RIGHT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из второй по порядку (правой) таблицы, даже если они не соответствуют условию. У записей правой таблицы, которые не соответствуют условию, значение столбца из левой таблицы будет NULL (неопределённым).

Пример 5.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS RIGHT OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| NULL | 45 | 65,00 |
В результирующей таблице, в отличие от таблицы из примера 1, есть запись с категорией 45 и ценой 65,00, но значение столбца Части (Part) у неё - NULL, так как эта запись имеет идентификатор категории, на которую нет ссылок в таблице Parts.
FULL OUTER JOIN (полное внешнее соединение)
Запрос с оператором FULL OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой (левой) и второй (правой) таблиц, даже если они не соответствуют условию. У записей, которые не соответствуют условию, значение столбцов из другой таблицы будет NULL (неопределённым).

Пример 6. База данных и таблицы - те же, что и в предыдущих примерах.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными как из таблицы Parts, так и из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS FULL OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
| NULL | 45 | 65,00 |
В результирующей таблице есть записи Книги (из левой таблицы) и с категорией 45 (из правой таблицы), причём у первой из них неопределённая цена (столбец из правой таблицы), а у второй - неопределённая часть (столбец из левой таблицы).
Псевдонимы соединяемых таблиц
В предыдущих запросах мы указывали с названиями извлекаемых столбцов из разных таблиц полные имена этих таблиц. Такие запросы выглядят громоздко: одно и то же слово повторяется несколько раз. Нельзя ли как-то упростить конструкцию? Оказывается, можно. Для этого следует использовать псевдонимы таблиц - их сокращённые имена. Псевдоним может состоять и из одной буквы. Возможно любое количество букв в псевдониме, главное, чтобы запрос после сокращения был понятен Вам самим. Общее правило: в секции запроса, определяющей соединение, то есть вокруг слова JOIN нужно указать полные имена таблиц, а за каждым именем должен следовать псевдоним таблицы.
Пример 7. Переписать запрос из примера 1 с использованием псевдонимов соединяемых таблиц.
Запрос будет следующим:
SELECT P.Part, C.Cat_ID AS Cat, C.Price FROM PARTS P INNER JOIN CATEGORIES C ON P.Cat = C.Cat_ID
Запрос вернёт то же самое, что и запрос в примере 1, но он гораздо компактнее.
JOIN и соединение более двух таблиц
Реляционные базы данных должны подчиняться требованиям целостности и неизбыточности данных, в связи с чем данные об одном бизнес-процессе могут содержаться не только в одной, двух, но и в трёх и более таблицах. В этих случаях для анализа данных используются цепочки соединённых таблиц: например, в одной (первой) таблице содержится некоторый количественный показатель, вторую таблицу с первой и третьей связывают внешние ключи - данные пересекаются, но только третья таблица содержит условие, в зависимости от которого может быть выведен количественный показатель из первой таблицы. И таблиц может быть ещё больше. При помощи оператора SQL JOIN в одном запросе можно соединить большое число таблиц. В таких запросах за одной секцией соединения следует другая, причём каждый следующий JOIN соединяет со следующей таблицей таблицу, которая была второй в предыдущем звене цепочки. Таким образом, синтаксис SQL запроса для соединения более двух таблиц следующий:
SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ_1 JOIN ИМЯ_ТАБЛИЦЫ_2 ON УСЛОВИЕ JOIN ИМЯ_ТАБЛИЦЫ_3 ON УСЛОВИЕ... JOIN ИМЯ_ТАБЛИЦЫ_M ON УСЛОВИЕ
Пример 8. База данных - та же, что и в предыдущих примерах. К таблицам Categories и Parts в этом примере добавится таблица Ads, содержащая данные об опубликованных на портале объявлениях. Приведём фрагмент таблицы Ads, в котором среди записей есть записи о тех объявлениях, срок публикации которых истекает 2018-04-02.
| A_Id | Part_ID | Date_start | Date_end | Text |
| 21 | 1 | "2018-02-11" | "2018-04-20" | "Продаю..." |
| 22 | 1 | "2018-02-11" | "2018-05-12" | "Продаю..." |
| ... | ... | ... | ... | ... |
| 27 | 1 | "2018-02-11" | "2018-04-02" | "Продаю..." |
| 28 | 2 | "2018-02-11" | "2018-04-21" | "Продаю..." |
| 29 | 2 | "2018-02-11" | "2018-04-02" | "Продаю..." |
| 30 | 3 | "2018-02-11" | "2018-04-22" | "Продаю..." |
| 31 | 4 | "2018-02-11" | "2018-05-02" | "Продаю..." |
| 32 | 4 | "2018-02-11" | "2018-04-13" | "Продаю..." |
| 33 | 3 | "2018-02-11" | "2018-04-12" | "Продаю..." |
| 34 | 4 | "2018-02-11" | "2018-04-23" | "Продаю..." |
Представим, что сегодня "2018-04-02", то есть это значение принимает функция CURDATE() - текущая дата . Требуется узнать, к каким категориям принадлежат объявления, срок публикации которых истекает сегодня. Названия категорий есть только в таблице CATEGORIES, а даты истечения срока публикации объявлений - только в таблице ADS. В таблице PARTS - части категорий (или проще, подкатегории) опубликованных объявлений. Но внешним ключом Cat_ID таблица PARTS связана с таблицей CATEGORIES, а таблица ADS связана внешним ключом Part_ID с таблицей PARTS. Поэтому соединяем в одном запросе три таблицы и этот запрос можно с максимальной корректностью назвать цепочкой.
Запрос будет следующим:
Результат запроса - таблица, содержащая названия двух категорий - "Недвижимость" и "Транспорт":
| Cat_name |
| Недвижимость |
| Транспорт |
CROSS JOIN (перекрестное соединение)
Использование оператора SQL CROSS JOIN в наиболее простой форме - без условия соединения - реализует операцию декартова произведения в реляционной алгебре . Результатом такого соединения будет сцепление каждой строки первой таблицы с каждой строкой второй таблицы. Таблицы могут быть записаны в запросе либо через оператор CROSS JOIN, либо через запятую между ними.
Пример 9. База данных - всё та же, таблицы - Categories и Parts. Реализовать операцию декартова произведения этих двух таблиц.
Запрос будет следующим:
SELECT (*) Categories CROSS JOIN Parts
Или без явного указания CROSS JOIN - через запятую:
SELECT (*) Categories , Parts
Запрос вернёт таблицу из 5 * 5 = 25 строк, фрагмент которой приведён ниже:
| Cat_ID | Cat_name | Price | Part_ID | Part | Cat |
| 10 | Стройматериалы | 105,00 | 1 | Квартиры | 505 |
| 10 | Стройматериалы | 105,00 | 2 | Автомашины | 205 |
| 10 | Стройматериалы | 105,00 | 3 | Доски | 10 |
| 10 | Стройматериалы | 105,00 | 4 | Шкафы | 30 |
| 10 | Стройматериалы | 105,00 | 5 | Книги | 160 |
| ... | ... | ... | ... | ... | ... |
| 45 | Техника | 65,00 | 1 | Квартиры | 505 |
| 45 | Техника | 65,00 | 2 | Автомашины | 205 |
| 45 | Техника | 65,00 | 3 | Доски | 10 |
| 45 | Техника | 65,00 | 4 | Шкафы | 30 |
| 45 | Техника | 65,00 | 5 | Книги | 160 |
Как видно из примера, если результат такого запроса и имеет какую-либо ценность, то это, возможно, наглядная ценность в некоторых случаях, когда не требуется вывести структурированную информацию, тем более, даже самую простейшую аналитическую выборку. Кстати, можно указать выводимые столбцы из каждой таблицы, но и тогда информационная ценность такого запроса не повысится.
Но для CROSS JOIN можно задать условие соединения! Результат будет совсем иным. При использовании оператора "запятая" вместо явного указания CROSS JOIN условие соединения задаётся не словом ON, а словом WHERE.
Пример 10. Та же база данных портала объявлений, таблицы Categories и Parts. Используя перекрестное соединение, соединить таблицы так, чтобы данные полностью пересекались по условию. Условие - совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts.
Запрос будет следующим:
Запрос вернёт то же самое, что и запрос в примере 1:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
И это совпадение не случайно. Запрос c перекрестным соединением по условию соединения полностью аналогичен запросу с внутренним соединением - INNER JOIN - или, учитывая, что слово INNER - не обязательное, просто JOIN.
Таким образом, какой вариант запроса использовать - вопрос стиля или даже привычки специалиста по работе с базой данных. Возможно, перекрёстное соединение с условием для двух таблиц может представляться более компактным. Но преимущество перекрестного соединения для более чем двух таблиц (это также возможно) весьма спорно. В этом случае WHERE-условия пересечения перечисляются через слово AND. Такая конструкция может быть громоздкой и трудной для чтения, если в конце запроса есть также секция WHERE с условиями выборки.
Реляционные базы данных и язык SQL
Продолжаем изучать основы SQL , и пришло время поговорить о простых объединениях JOIN. И сегодня мы рассмотрим, как объединяются данные по средствам операторов LEFT JOIN, RIGHT JOIN, CROSS JOIN и INNER JOIN , другими словами, научимся писать запросы, которые объединяют данные, и как обычно изучать все это будем на примерах.
Объединения JOIN очень важны в SQL, так как без умения писать запросы с объединением данных разных объектов, просто не обойтись программисту SQL, да и просто админу который время от времени выгружает какие-то данные из базы данных, поэтому это относится к основам SQL и каждый человек, который имеет дело с SQL, должен иметь представление, что это такое.
Примечание! Все примеры будем писать в Management Studio SQL Server 2008.
Мы с Вами уже давно изучаем основы SQL, и если вспомнить начинали мы с оператора select , и вообще было уже много материала на этом сайте по SQL, например:
И много другого, даже уже рассматривали объединения union и union all , но, так или иначе, более подробно именно об объединениях join мы с Вами не разговаривали, поэтому сегодня мы восполним этот пробел в наших знаниях.
И начнем мы как обычно с небольшой теории.
Объединения JOIN — это объединение двух или более объектов базы данных по средствам определенного ключа или ключей или в случае cross join и вовсе без ключа. Под объектами здесь подразумевается различные таблицы, представления (views) , табличные функции или просто подзапросы sql , т.е. все, что возвращает табличные данные.
Объединение SQL LEFT и RIGHT JOIN
LEFT JOIN – это объединение данных по левому ключу, т.е. допустим, мы объединяем две таблицы по left join, и это значит что все данные из второй таблицы подтянутся к первой, а в случае отсутствия ключа выведется NULL значения, другими словами выведутся все данные из левой таблицы и все данные по ключу из правой таблицы.
RIGHT JOIN – это такое же объединение как и Left join только будут выводиться все данные из правой таблицы и только те данные из левой таблицы в которых есть ключ объединения.
Теперь давайте рассматривать примеры, и для начала создадим две таблицы:
CREATE TABLE ( (18, 0) NULL, (50) NULL) ON GO CREATE TABLE ( (18, 0) NULL, (50) NULL) ON GO
Вот такие простенькие таблицы, И я для примера заполнил их вот такими данными:
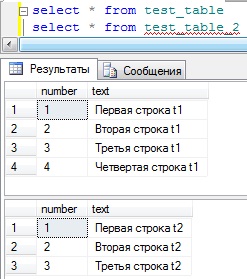
Теперь давайте напишем запрос с объединением этих таблиц по ключу number, для начала по LEFT:

SELECT t1.number as t1_number,t1.text as t1_text, t2.number as t2_number, t2.text as t2_text FROM test_table t1 LEFT JOIN test_table_2 t2 ON t1.number=t2.number
Как видите, здесь данные из таблицы t1 вывелись все, а данные из таблицы t2 не все, так как строки с number = 4 там нет, поэтому и вывелись NULL значения.
А что будет, если бы мы объединяли по средствам right join, а было бы вот это:

SELECT t1.number as t1_number,t1.text as t1_text, t2.number as t2_number, t2.text as t2_text FROM test_table t1 RIGHT JOIN test_table_2 t2 ON t1.number=t2.number
Другими словами, вывелись все строки из таблицы t2 и соответствующие записи из таблицы t1, так как все те ключи, которые есть в таблице t2, есть и в таблице t1, и поэтому у нас нет NULL значений.
Объединение SQL INNER JOIN
Inner join – это объединение когда выводятся все записи из одной таблицы и все соответствующие записи из другой таблице, а те записи которых нет в одной или в другой таблице выводиться не будут, т.е. только те записи которые соответствуют ключу. Кстати сразу скажу, что inner join это то же самое, что и просто join без Inner. Пример:

SELECT t1.number as t1_number,t1.text as t1_text, t2.number as t2_number, t2.text as t2_text FROM test_table t1 INNER JOIN test_table_2 t2 on t1.number=t2.number
А теперь давайте попробуем объединить наши таблицы по двум ключам, для этого немного вспомним, как добавлять колонку в таблицу и как обновить данные через update, так как в наших таблицах всего две колонки, и объединять по текстовому полю как-то не хорошо. Для этого добавим колонки:
ALTER TABLE test_table ADD number2 INT ALTER TABLE test_table_2 ADD number2 INT
Обновим наши данные, просто проставим в колонку number2 значение 1:
UPDATE test_table SET number2 = 1 UPDATE test_table_2 SET number2 = 1
И давайте напишем запрос с объединением по двум ключам:
SELECT t1.number as t1_number,t1.text as t1_text, t2.number as t2_number, t2.text as t2_text FROM test_table t1 INNER JOIN test_table_2 t2 ON t1.number=t2.number AND t1.number2=t2.number2
И результат будет таким же, как и в предыдущем примере:

Но если мы, допустим во второй таблице в одной строке изменим, поле number2 на значение скажем 2, то результат будет уже совсем другой.
UPDATE test_table_2 set number2 = 2 WHERE number=1
Запрос тот же самый, а вот результат:

Как видите, по второму ключу у нас одна строка не вывелась.
Объединение SQL CROSS JOIN
CROSS JOIN – это объединение SQL по которым каждая строка одной таблицы объединяется с каждой строкой другой таблицы. Лично у меня это объединение редко требуется, но все равно иногда требуется, поэтому Вы также должны уметь его использовать. Например, в нашем случае получится, конечно, не понятно что, но все равно давайте попробуем, тем более синтаксис немного отличается:

SELECT t1.number as t1_number,t1.text as t1_text, t2.number as t2_number, t2.text as t2_text FROM test_table t1 CROSS JOIN test_table_2 t2
Здесь у нас каждой строке таблицы test_table соответствует каждая строка из таблицы test_table_2, т.е. в таблице test_table у нас 4 строки, а в таблице test_table_2 3 строки 4 умножить 3 и будет 12, как и у нас вывелось 12 строк.
И напоследок, давайте покажу, как можно объединять несколько таблиц, для этого я, просто для примера, несколько раз объединю нашу первую таблицу со второй, смысла в объединение в данном случае, конечно, нет но, Вы увидите, как можно это делать и так приступим:

SELECT t1.number as t1_number, t1.text as t1_text, t2.number as t2_number, t2.text as t2_text, t3.number as t3_number, t3.text as t3_text, t4.number as t4_number, t4.text as t4_text FROM test_table t1 LEFT JOIN test_table_2 t2 on t1.number=t2.number RIGHT JOIN test_table_2 t3 on t1.number=t3.number INNER JOIN test_table_2 t4 on t1.number=t4.number
Как видите, я здесь объединяю и по left и по right и по inner просто, для того чтобы это было наглядно.
С объединениями я думаю достаточно, тем более ничего сложного в них нет. Но на этом изучение SQL не закончено в следующих статьях мы продолжим, а пока тренируйтесь и пишите свои запросы. Удачи!
Разработка любой базы данных подразумевает не только создание и наполнение таблиц разнообразной информацией, но и дальнейшую работу с данными. Для корректного выполнения разнообразных задач по выбору данных из таблиц и формированию отчетов, используется стандартная конструкция Select.
Выборки данных из таблиц
Если рассматривать задачу выбора данных или построения некоторого отчета, можно определить уровень сложности данной операции. Как правило, при работе с серьезными (по объему информации) базами данных, которые формируются, например, в интернет-магазинах или крупных компаниях, выборка данных не будет ограничиваться лишь одной таблицей. Как правило, выборки могут быть из довольно большого количества не только связанных между собой таблиц, но и вложенных запросов/подзапросов, которые составляет сам программист, в зависимости от поставленной перед ним задачи. Для выборки из одной таблицы можно использовать простейшую конструкцию:
| Select * from Person |
где Person - имя таблицы, из которой необходимо сделать выборку данных.
Если же будет необходимость выбрать данные из нескольких таблиц, можно использовать одну из стандартных конструкций для объединения нескольких таблиц.
Способы подключения дополнительных таблиц
Если рассматривать использование такого рода конструкций на начальном уровне, то можно выделить следующие механизмы подключения необходимого количества таблиц для выборки, а именно:
- Оператор Inner Join.
- Left Join или, это второй способ записи, Left Outer Join.
- Cross Join.
- Full Join.
Использование операторов объединения таблиц на практике можно усвоить, рассмотрев применение оператора SQL - Inner Join. Пример его использования будет выглядеть следующим образом:
Select * from Person |
Язык SQL и оператор Join Inner Join можно использовать не только для объединения двух и более таблиц, но и для подключения иных подзапросов, что значительно облегчает работу администраторов базы данных и, как правило, может значительно ускорить выполнение определенных, сложных по структуре запросов.
Объединение данных в таблицах построчно

Если рассматривать подключение большого количества подзапросов и сборку данных в единую таблицу строка за строкой, то можно использовать также операторы Union, и Union All.
Применение этих конструкций будет зависеть от поставленной перед разработчиком задачи и результата, которого он хочет достичь в итоге.
Описание оператора Inner Join
В большинстве случаев для объединения нескольких таблиц в языке SQL используется оператор Inner Join. Описание Inner Join в SQL довольно простое для понимания среднестатистического программиста, который только начинает разбираться в базах данных. Если рассмотреть описание механизма работы этой конструкции, то получим следующую картину. Логика оператора в целом построена на возможности пересечения и выборки только тех данных, которые есть в каждой из входящих в запрос таблиц.
Если рассмотреть такую работу с точки зрения графической интерпретации, то получим структуру оператора SQL Inner Join, пример которой можно показать с помощью следующей схемы:

К примеру, мы имеем две таблицы, схема которых показана на рисунке. Они в свою очередь, имеют разное количество записей. В каждой из таблиц есть поля, которые связаны между собой. Если попытаться пояснить работу оператора исходя из рисунка, то возвращаемый результат будет в виде набора записей из двух таблиц, где номера связанных между собой полей совпадают. Проще говоря, запрос вернет только те записи (из таблицы номер два), данные о которых есть в таблице номер один.
Синтаксис оператора Inner Join
Как уже говорилось ранее, оператор Inner Join, а именно его синтаксис, необычайно прост. Для организации связей между таблицами в пределах одной выборки достаточно будет запомнить и использовать следующую принципиальную схему построения оператора, которая прописывается в одну строчку программного SQL-кода, а именно:
- Inner Join [Имя таблицы] on [ключевое поле из таблицы, к которой подключаем] = [Ключевому полю подключаемой таблицы].
Для связи в данном операторе используются главные ключи таблиц. Как правило, в группе таблиц, которые хранят информацию о сотрудниках, ранее описанные Person и Subdivision имеют хотя бы по одной похожей записи. Итак, рассмотрим подробнее Inner Join, пример которого был показан несколько ранее.
Пример и описание подключения к выборке одной таблицы
У нас есть таблица Person, где хранится информация обо всех сотрудниках, работающих в компании. Сразу отметим, что главным ключем данной таблицы является поле - Pe_ID. Как раз по нему и будет идти связка.
Вторая таблица Subdivision будет хранить информацию о подразделениях, в которых работают сотрудники. Она, в свою очередь, связана с помощью поля Su_Person с таблицей Person. О чем это говорит? Исходя из схемы данных можно сказать, что в таблице подразделений для каждой записи из таблицы «Сотрудники» будет информация об отделе, в котором они работают. Именно по этой связи и будет работать оператор Inner Join.
Для более понятного использования рассмотрим оператор SQL Inner Join (примеры его использования для одной и двух таблиц). Если рассматривать пример для одной таблицы, то тут все довольно просто:
Select * from Person Inner join Subdivision on Su_Person = Pe_ID |
Пример подключения двух таблиц и подзапроса

Оператор SQL Inner Join, примеры использования которого для выборки данных из нескольких таблиц можно организовать вышеуказанным образом, работает по чуть усложненному принципу. Для двух таблиц усложним задачу. Скажем, у нас есть таблица Depart, в которой хранится информация обо всех отделах в каждом из подразделений. В в эту таблицу записан номер подразделения и номер сотрудника и нужно дополнить выборку данных названием каждого отдела. Забегая вперед, стоит сказать, что для решения этой задачи можно воспользоваться двумя методами.
Первый способ заключается в подключении таблицы отделов к выборке. Организовать запрос в этом случае можно таким образом:
Стоит отметить, что такая конструкция не всегда может ускорить работу запроса. Иногда бывают случаи, когда приходится использовать дополнительно выборку данных во временную таблицу (если их объем слишком большой), а потом ее объединять с основной выборкой.
Пример использования оператора Inner Join для выборок из большого количества таблиц
Построение сложных запросов подразумевает использование для выборки данных значительного количества таблиц и подзапросов, связанных между собой. Этим требованиям может удовлетворить SQL Inner Join синтаксис. Примеры использования оператора в данном случаем могут усложняться не только выборками из многих мест хранения данных, но и с большого количества вложенных подзапросов. Для конкретного примера можно взять выборку данных из системных таблиц (оператор Inner Join SQL). Пример - 3 таблицы - в этом случае будет иметь довольно сложную структуру.

В данном случае подключено (к основной таблице) еще три дополнительно и введено несколько условий выбора данных.
При использовании оператора Inner Join стоит помнить о том, что чем сложнее запрос, тем дольше он будет реализовываться, поэтому стоит искать пути более быстрого выполнения и решения поставленной задачи.

Заключение
В итоге хотелось бы сказать одно: работа с базами данных - это не самое сложное, что есть в программировании, поэтому при желании абсолютно каждый человек сможет овладеть знаниями по построению баз данных, а со временем, набравшись опыта, получится работать с ними на профессиональном уровне.